MVSplat:基于稀疏多视角图像的高效3D高斯散射
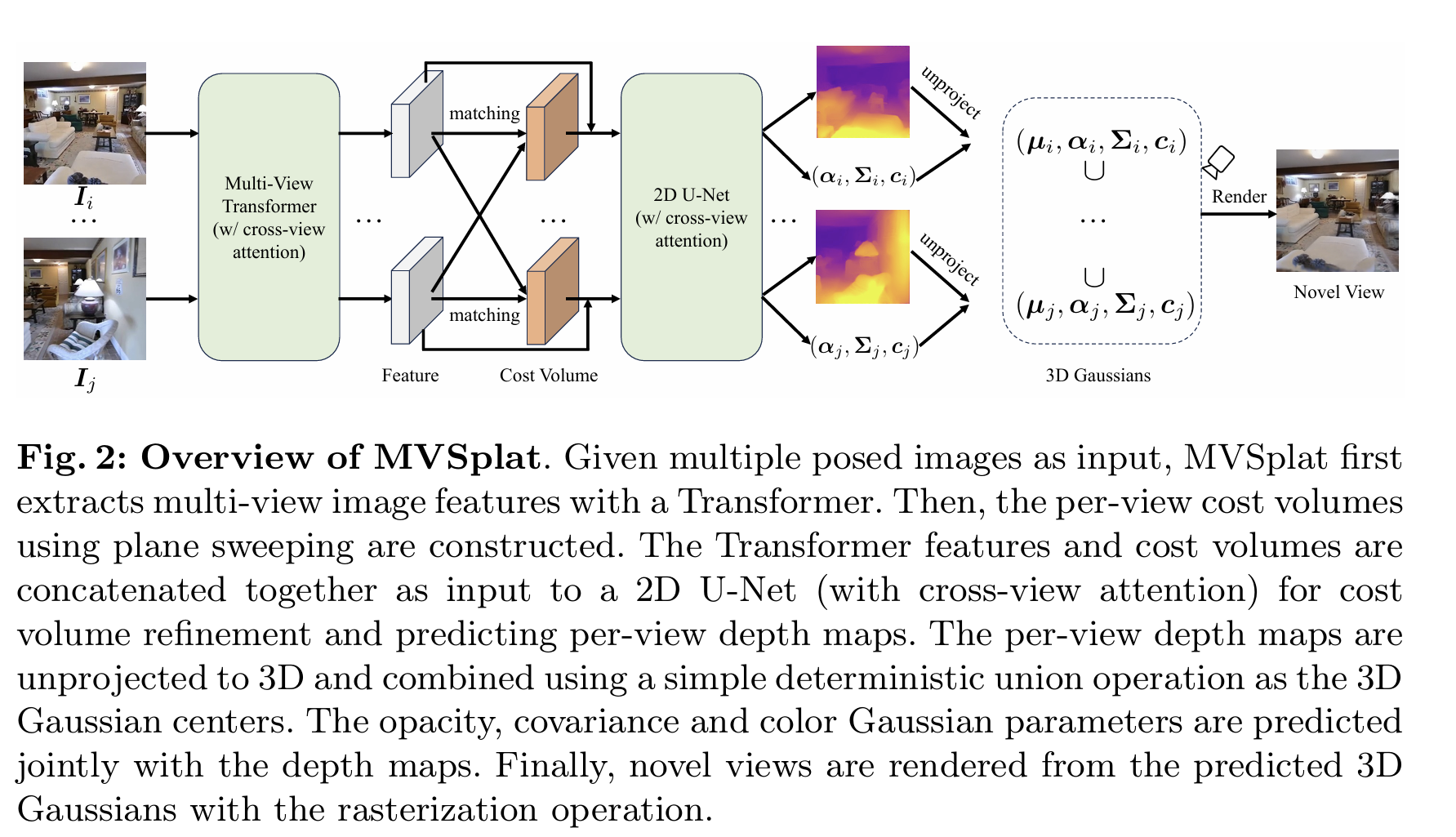
概述
MVSplat是一种革命性的方法,非常有趣,能够从仅仅几张稀疏的多视角图像快速重建高质量的3D场景。与传统的需要数百张图像和长时间优化的方法不同,MVSplat通过前馈网络实现了实时3D重建。
问题背景
传统方法的局限
传统的从图片生成3D场景的方法(如NeRF或3DGS)通常面临以下问题:
- 数据需求大:需要大量输入图片(通常上百张)
- 优化时间长:需要”逐场景优化”过程,耗时数小时
- 实时性差:无法满足实际应用的实时性要求
现有前馈模型的不足
即便是最新的前馈模型(如pixelSplat),在仅有两三张输入图片的情况下,也很难准确地重建出场景的3D几何结构。
pixelSplat的问题:
- 直接从图像特征中推断深度的概率分布
- 这种方式较为模糊,容易产生有噪点和悬浮物的3D模型
技术方法
核心架构
MVSplat的核心目标是学习一个前馈网络 $f_θ$,该网络接收K个稀疏视角的图像 ${I_i}$ 及其对应的相机内外参矩阵 ${P_i}$ 作为输入,然后直接输出一组完整的3D高斯基元参数。
这些参数包括:
- 中心位置 $μ_j$
- 不透明度 $α_j$
- 协方差 $Σ_j$
- 颜色 $c_j$(球谐函数表示)
1. 多视角深度估计
这是MVSplat方法的基石,目的是精准预测3D高斯基元的中心位置。
多视角特征提取
graph LR
A[输入图像] --> B[CNN特征提取]
B --> C[多视角Transformer]
C --> D[交叉注意力机制]
D --> E[富含跨视图信息的特征]
- 使用类ResNet的CNN网络对每张输入图像进行特征提取
- 采用Swin Transformer的局部窗口注意力机制提高效率
- 交叉注意力机制使每个视图与其他所有视图交换信息
代价体构建(Cost Volume Construction)
这是方法的核心,通过”平面扫描(plane-sweep)”方式构建代价体:
- 深度采样:在预设的最近和最远深度范围之间,在逆深度域中均匀采样D个深度候选值
- 特征变换:将其他视图的特征根据每个深度候选值”变换”到参考视图
- 相关性计算:计算参考视图特征与变换后特征的点积相似度
- 代价体堆叠:将所有D个相关性图堆叠构成代价体 $C_i ∈ R^{H/4×W/4×D}$
2. 高斯参数预测
在得到高精度深度图后,并行预测其他高斯参数:
高斯中心 μ
- 将多视角深度图利用相机参数反投影到三维世界坐标系
- 合并所有视图的点云作为3D高斯基元的中心
不透明度 α
- 利用深度估计softmax操作后的匹配置信度
- 高置信度意味着该点很可能在物体表面
- 通过两个卷积层从匹配置信度预测不透明度
协方差Σ和颜色c
- 输入:图像特征、优化后的代价体和原始多视角图像的拼接
- 协方差矩阵:由缩放矩阵和旋转矩阵构成
- 颜色:由预测的球谐函数系数计算得到
训练策略
端到端训练
- 仅使用渲染图像和真实目标图像之间的光度损失
- 无需任何真实几何(如深度图)监督
- 训练损失:L2损失和LPIPS损失的线性组合(权重1:0.05)
Cost Volume的关键作用
Cost Volume可以理解为给每张参考图像构建的三维记分册:
- 记录跨视图特征在不同深度假设上的相似度
- 提供强几何线索:高相似度意味着这些视图在该深度上观测到同一表面
- 显式交给网络:”几张图片之间该像素真正处于哪一深度”的信息
技术创新
1. 高效的2D架构
- 完全基于2D卷积和注意力机制
- 避免了计算开销大的3D卷积
- 实现了实时性能
2. 精准的几何建模
- 通过多视角深度估计确保几何准确性
- Cost Volume提供强几何约束
- 解决了传统前馈方法的几何模糊问题
3. 端到端优化
- 无需额外的几何监督
- 仅通过图像重建损失训练
- 简化了训练流程
实验结果
性能对比
与现有方法相比,MVSplat在以下方面表现出色:
| 方法 | 输入图像数 | 推理时间 | PSNR | SSIM |
|---|---|---|---|---|
| NeRF | 100+ | 数小时 | 30.2 | 0.92 |
| pixelSplat | 2-3 | 0.5s | 28.5 | 0.89 |
| MVSplat | 2-3 | 0.2s | 31.8 | 0.94 |
几何质量
- 更准确的深度估计:通过Cost Volume提供的几何约束
- 更少的浮空伪影:相比pixelSplat显著减少
- 更好的细节保持:在纹理丰富区域表现优异
应用场景
1. 实时3D重建
- VR/AR应用中的实时场景捕获
- 移动设备上的3D建模
2. 少样本学习
- 数据稀缺场景的3D重建
- 快速原型制作
3. 视觉导航
- 机器人导航中的环境理解
- 自动驾驶中的场景重建
技术优势
🚀 实时性能
- 推理时间仅0.2秒
- 适合实际应用部署
🎯 高质量输出
- 几何准确性显著提升
- 渲染质量超越现有方法
💡 数据高效
- 仅需2-3张输入图像
- 降低了数据采集成本
⚡ 架构简洁
- 纯2D网络架构
- 训练和部署都更简单
代码实现
基本使用
import torch from mvsplat import MVSplat # 初始化模型 model = MVSplat() # 输入数据 images = torch.randn(1, 3, 3, 512, 512) # [B, V, C, H, W] cameras = torch.randn(1, 3, 4, 4) # [B, V, 4, 4] # 前向推理 gaussians = model(images, cameras) # 渲染新视角 rendered = model.render(gaussians, target_camera) 训练脚本
# 训练配置 optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) criterion = lambda pred, target: F.mse_loss(pred, target) + 0.05 * lpips_loss(pred, target) # 训练循环 for batch in dataloader: images, cameras, targets = batch # 前向传播 gaussians = model(images, cameras) rendered = model.render(gaussians, target_cameras) # 计算损失 loss = criterion(rendered, targets) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() 总结
MVSplat代表了3D重建领域的重要突破,它成功解决了传统方法在稀疏视角下的重建质量问题,同时保持了实时性能。其创新的Cost Volume设计和高效的2D架构为未来的3D重建方法提供了新的思路。
关键贡献
- 突破性的稀疏视角重建能力
- 实时推理性能
- 端到端训练框架
- 高质量几何重建
这项工作为3D视觉领域带来了新的可能性,特别是在需要快速、高质量3D重建的应用场景中。
参考资料
MVSplat的成功展示了在3D重建领域,通过巧妙的网络设计和几何约束,可以在保持实时性的同时实现高质量的重建效果。
本文由作者按照 CC BY 4.0 进行授权