SPLATFORMER: POINT TRANSFORMER FOR ROBUST3D GAUSSIAN SPLATTING
2025 ICLR spotlight(我很喜欢这一篇,Point Transformer我可太熟了)
概括
极端视角下优化gaussian splatting表现
背景:
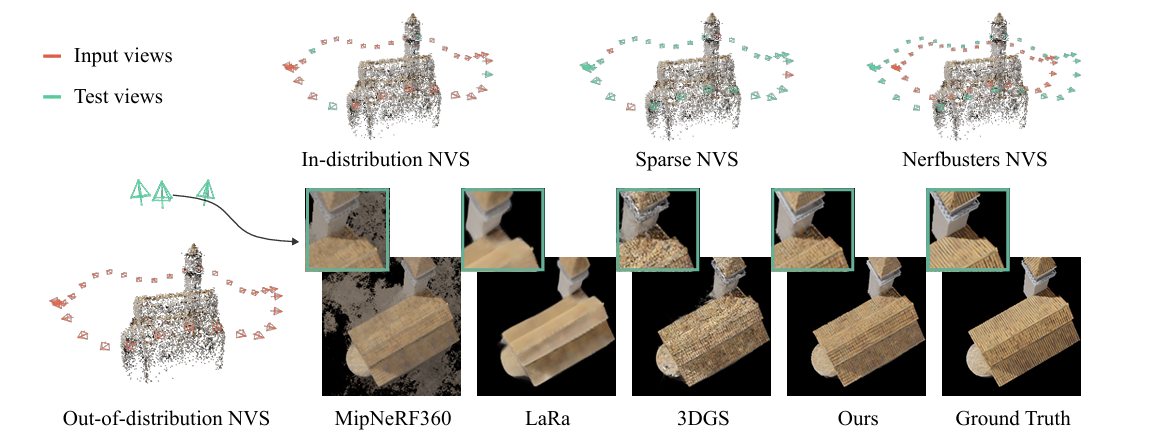
- 3DGS的局限性:尽管3DGS技术在生成逼真的三维场景方面表现出色,但它的渲染质量在面对“分布外(Out-of-Distribution, OOD)”的测试视角时会急剧下降。 简单来说,如果你只从低角度拍摄一个物体来训练3DGS模型,然后想从物体的正上方(一个从未见过的角度)来渲染它,生成的图像会出现很多瑕疵,比如拉伸变形的“浮空”或“条状”伪影。
- 新挑战的提出:研究者将这个问题定义为一个新的、具有实际意义的挑战,称为“分布外新视角合成(OOD-NVS)”,并指出当前多数方法都忽略了这个问题。
方法
- 初始3DGS生成:首先,使用有限的、有偏差的输入视角(例如,仅低角度视图)来训练一个标准的3DGS模型,得到一个初步但有缺陷的高斯点云集合。
- SplatFormer进行优化:接着,将这个有缺陷的3DGS点云集合输入到SplatFormer模型中。SplatFormer会通过一次前向传播(a single forward pass)来对这些高斯点进行智能化的提炼和修正。
- 输出高质量结果:SplatFormer输出一组经过优化的新3DGS点云,这组点云在渲染那些从未见过的OOD视角时,能够显著减少伪影,生成更清晰、更符合三维结构的结果。
SplatFormer 的核心架构
SplatFormer 的设计灵感来源于Point Transformer ,因为它非常适合处理像3DGS这样的无序点云数据 。其内部结构如图3下方所示,主要包含一个编码器和一个解码器 。
核心思想:预测残差 (Residual Prediction)
SplatFormer 并不直接预测一个全新的、完美的高斯点云。相反,它预测的是对初始点云的修正量(或称残差 ΔGk) 。最终优化的点云是初始点云加上这个修正量:Gk′=Gk+ΔGk 。这样做可以使训练更稳定、更容易收敛 。
- 点变换器编码器 (Point Transformer Encoder fθ):
- 它将初始的3DGS点云作为输入 。
- 通过一个包含多层注意力模块 (Attention Blocks) 和池化层 (Grid Pooling) 的层级化网络结构,来捕捉高斯点之间的复杂空间关系和上下文信息 。
- 最终,为每个输入的高斯点生成一个高维度的“特征向量”vk ,这个向量浓缩了该点及其邻域的几何与外观信息。
- 特征解码器 (Feature Decoder gθ):
- 解码器接收编码器输出的特征向量vk 以及原始的高斯点属性 Gk 。
- 它包含五个独立的分支(Heads),分别负责预测五种属性的残差(修正量):位置(Δpk)、尺寸(Δsk)、不透明度(Δαk)、旋转(Δqk)和颜色(Δak) 。
- 每个分支都是一个简单的多层感知机(MLP)网络 。
SplatFormer 的训练过程 (Learning a Data-driven Prior)
为了让SplatFormer拥有“修复”能力,研究者们对其进行了大规模的监督训练。
- 构建大规模数据集:
- 他们使用了两个大型3D模型库ShapeNet 和 Objaverse-1.0,总共包含约8万个3D场景 。
- 对于每个3D模型,他们都用程序生成两组图像:一组是低角度的“输入视图”,另一组是高角度的“OOD视图” 。
- 然后,用低角度视图生成一个有缺陷的初始3DGS。这样,就得到了大量的“有缺陷的3DGS -> 正确的OOD图像”训练对 。
- 定义训练目标 (Loss Function):
- SplatFormer 的训练目标是渲染损失 (Rendering Loss) 。
- 在训练的每一步,模型会输出一个优化后的点云集{Gk′}k=1K。然后,系统会用这个点云集去渲染出OOD视角的图像 。
- 将渲染出的图像与真实的OOD图像进行比较,计算它们之间的差异。这个差异由公式(7)定义,它结合了两种损失:一种是像素级别的 L1 损失,另一种是更符合人类感知的 LPIPS 损失 。
- 通过反向传播最小化这个渲染损失,SplatFormer就能学会如何调整初始点云的属性,使得最终渲染出的OOD图像尽可能接近真实图像。通过在海量数据上进行这种训练,SplatFormer就学会了一种通用的、数据驱动的“先验知识”,知道如何将有缺陷的3DGS变得更加三维一致和鲁棒 。
贡献
创建了新的评估基准以测试OOD-NVS
开发了SplatTransformer
本文由作者按照 CC BY 4.0 进行授权