HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video
核心
- 核心目标:仅用单目交互视频,不依赖物体模板与类别先验,同时重建“可动的手 + 被握持的未知物体”的高质量3D表面与姿态。
- 关键思想:把“手与物体”作为互补线索来联合建模与渲染:手的几何与接触约束能反推被握物体形状,反之亦然。并通过“分解式隐式模型 + 体渲染 + 交互约束下的姿态优化”完成可分离(disentangled)的重建。
问题/背景:
- 现有很多方法要么需要已知物体模板(很难泛化到野外),要么依赖少量的有标注的手-物体3D数据(泛化差),或只做“手持扫描”但不处理手的关节运动。
- 本文提出类别无关(category-agnostic)、无模板、单目视频、手可关节运动的联合重建框架。
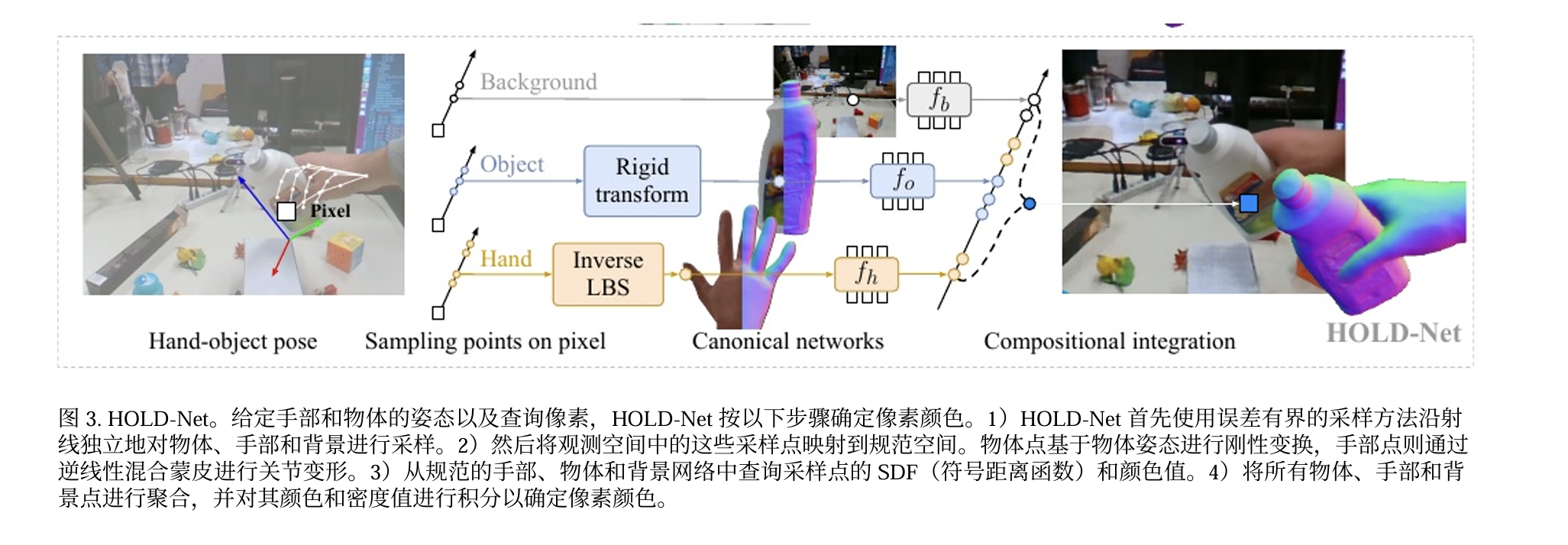
方法(四阶段 Pipeline)
- 姿态初始化:用现成手部回归器估计 MANO 参数与手的位姿;用分割得到物体区域后对物体做 SfM 估计每帧位姿(含尺度),并做一个小优化把手与物体在同一尺度/坐标中对齐且鼓励接触。
- HOLD-Net 预训练:以初始化的姿态为条件,训练一个组合式隐式场(手/物体/背景各一套 SDF+颜色网络)并用体渲染监督,先获得粗几何。
- 姿态细化:基于预训练几何,用接触损失 + 可微栅格化掩码一致性联合优化”手/物体”的外参与手形状、物体尺度等姿态参数。
- 最终训练:用细化后的姿态从头再训练网络与每帧潜码,得到高保真手与物体表面。
贡献/成果
- 首个类别无关、单目、手可关节运动且无模板的“手-物体联合”重建框架。
- 提出可组合的隐式SDF+体渲染模型,在同一射线内分而治之地建模手/物体/背景并合成。
- 交互约束驱动的姿态细化(接触+遮挡感知掩模)显著减少深度歧义,提升相对布局与最终几何。
- 在 HO3D 与野外视频上,无3D标注的前提下超越多种全监督/强先验基线。
本文由作者按照 CC BY 4.0 进行授权