GaussTR: Foundation Model-Aligned Gaussian Transformer for Self-Supervised 3D Spatial Understanding
问题/背景
- 3D 语义占据预测 (Semantic Occupancy Prediction) 需要对场景体素进行几何与语义标注,但传统方法依赖密集体素和大量人工标注,既算力高又难以泛化。
- 现有自监督方法常采用体素渲染或 NeRF,仍然计算量大且依赖 2D 伪标签,遇到真实分布变化时表现不稳。
方法
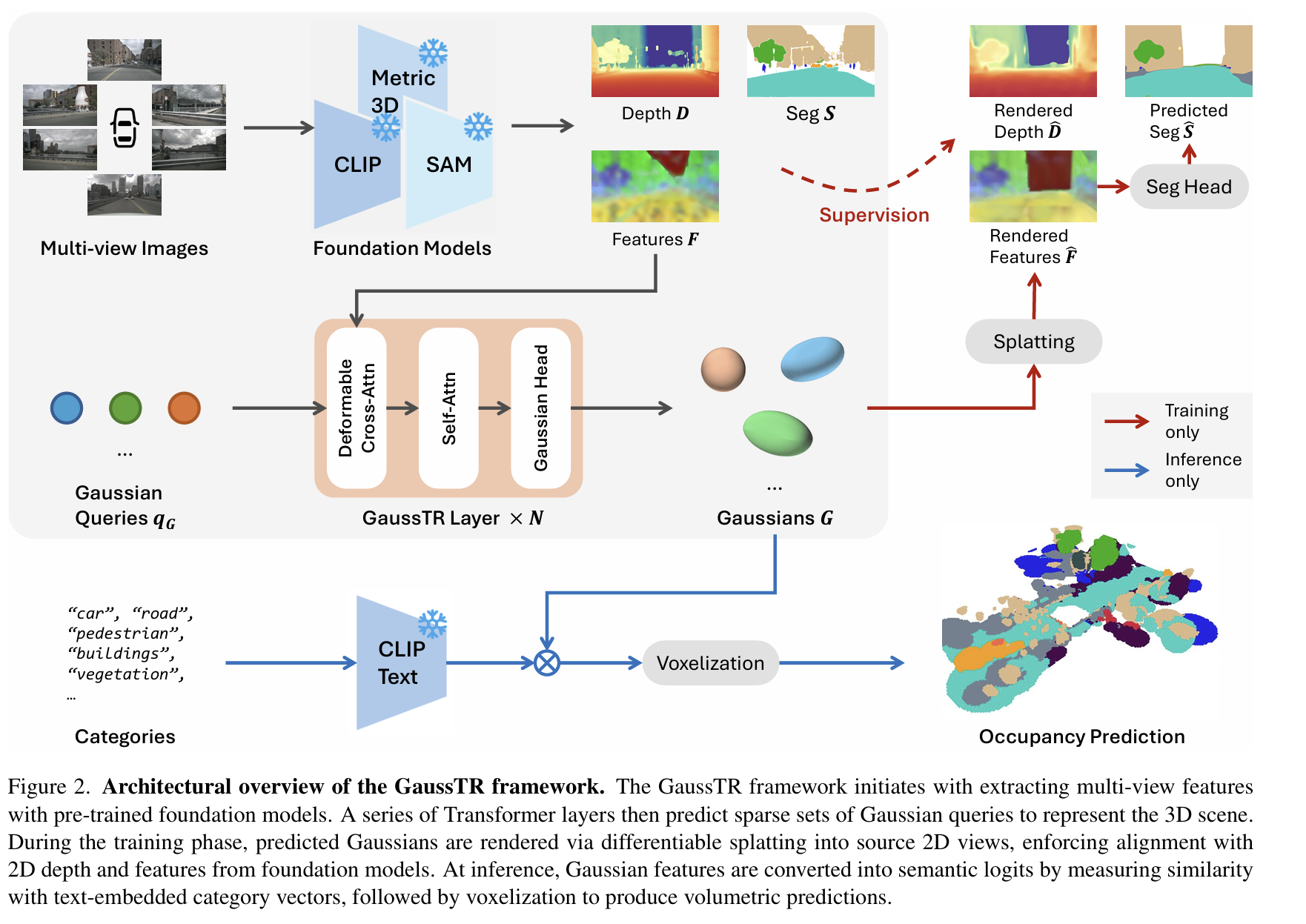
- 与基础模型对齐,实现自监督学习:这是该方法最关键的创新。GaussTR 利用了“3D高斯溅射”(Gaussian Splatting)技术的可微分渲染特性,将预测出的3D高斯“拍扁”渲染回2D图像视角 。然后,它并不与人工标注的数据进行比较,而是将渲染出的2D特征图与强大的视觉基础模型(Vision Foundation Models, 如CLIP, DINOv2)提取的特征进行对齐 。通过这种方式,模型可以在没有3D标签的情况下进行自监督学习,从而掌握丰富的3D空间理解能力 。
- 用稀疏高斯表示场景:不同于密集的体素,GaussTR 使用一个 Transformer 网络,通过一次前向传播,直接预测出一组稀疏的3D高斯函数来表示整个三维场景 。这种方式极大地降低了场景表示的参数量和计算复杂度 。
1. 前馈高斯”拍平”(Feedforward Gaussian Splatting)
这是模型构建三维表示的基础。
- 输入与初始化:
- 模型首先使用预训练的视觉基础模型(VFM),例如 CLIP 和 Metric3D V2,从多视角的输入图像中提取特征图F 和深度图 D。
- 模型的核心是一组可学习的高斯查询(Gaussian Queries) qG。在初始化时,每个查询都与一个二维像素位置μ2D 相关联。
- 每个三维高斯函数G 由一系列属性参数化:一个三维中心点 μ3D,一个可分解为缩放因子 S 和旋转四元数 R 的三维协方差矩阵 Σ,一个密度值 α,以及一个特征向量 fG(取代了传统高斯”拍平”中的球谐函数)。
- 高斯函数的初始三维位置μ3D 是通过将二维位置 μ2D 和从深度图 D 中采样的深度值 dG 利用相机内外参反向投影到世界坐标系得到的。初始的缩放和旋转也根据透视原理和相机朝向进行设定。
- 通过 Transformer 进行优化:
- 初始化的查询随后被送入多层GaussTR Transformer 解码器进行优化。
可变形交叉注意力(Deformable Cross-Attention):在每一层中,模型使用可变形注意力机制,让每个高斯查询根据其投影回二维图像的位置 μ2D,从多尺度的二维特征图 F 中有选择性地聚合相关信息。
自注意力(Self-Attention):随后,模型在所有高斯查询之间应用自注意力机制。为了让模型理解三维空间关系,高斯函数的三维中心点位置编码(Positional Encodings, PE)被加入到自注意力的查询(queries)和键(keys)中。这一步对于捕捉场景的全局上下文至关重要。
- 高斯参数预测:
- 经过 Transformer 层处理后,优化的查询向量qG 被送入一个专用的高斯头(Gaussian Head),该头部由多个多层感知机(MLP)组成。
- 这些 MLP 负责预测高斯参数的更新量(Δμ3D、ΔR、ΔS)以及最终的密度 α 和特征 fG。这些参数在 Transformer 的每一层后都会被迭代式地优化。
2. 视觉基础模型(VFM)对齐的自监督学习
这是模型训练的核心,它使得 GaussTR 无需昂贵的三维标注。
- 渲染过程:
- 在训练的每一步,模型将预测出的三维高斯集合G 通过可微分的高斯”拍平”技术渲染回原始的相机视角,生成渲染后的特征图 F^ 和深度图 D^。
- 为了提高特征渲染的效率,论文采用主成分分析(PCA)来降低 VFM 特征的维度,然后再进行渲染和损失计算。
- 渲染过程通过对所有高斯函数进行 alpha-blending 来计算每个像素的最终特征和深度值。
-
监督损失函数:
特征损失(Lfeat):通过计算渲染特征图 F^ 和 VFM 提取的原始特征图 F 之间的余弦相似度损失,来保证预测的高斯函数所携带的语义特征与基础模型的理解一致。
深度损失(Ldepth):为了保证几何结构的准确性,模型使用渲染深度图 D^ 和 VFM 预测的原始深度图 D 进行监督。该损失结合了
尺度不变对数损失(SILog Loss)和L1 损失。
分割损失(Lseg)(可选):为了优化语义边界,模型可以选择性地加入一个辅助的分割任务。一个辅助的分割头会基于渲染出的特征
F^ 预测分割图 S^,并使用 Grounded SAM 等模型生成的二维分割伪标签 S 通过交叉熵损失进行监督。
最终的总损失是以上各项损失的加权和。
3. 开放词汇占据预测
当模型训练完成后,它可以进行零样本、开放词汇的推理。
- 推理过程:
- 对于任何用户指定的文本类别列表(例如,”汽车”、”行人”、”建筑”),模型首先使用 VFM 的文本编码器(如 CLIP Text Encoder)为每个类别生成文本原型嵌入 fT。
- 然后,通过计算每个预测出的高斯函数的特征向量$f_G$ 与所有文本原型嵌入 fT 的点积相似度,并经过 Softmax 函数,得到该高斯函数属于每个类别的概率,即语义 logits lG。
- 最后,将这些带有语义 logits 的高斯函数进行体素化(Voxelization),即根据它们在三维空间中的位置和密度,将它们的语义信息累加到对应的体素网格中,从而生成最终的体积式语义占据预测结果。
值得注意的是,在推理过程中,用于辅助训练的分割头会被停用,这保证了模型对于任意新类别的零样本预测能力。
实验
贡献/成果
- 稀疏高斯场景表示:提出了一种通过前馈 Transformer 预测稀疏高斯函数来建模三维场景的新方法,取代了计算密集的体素网格。
- 基础模型对齐的自监督学习:利用可微分的高斯“拍平”技术,将三维表征与基础模型对齐,实现了自监督学习,从而支持开放词汇的占据预测,无需显式标签。
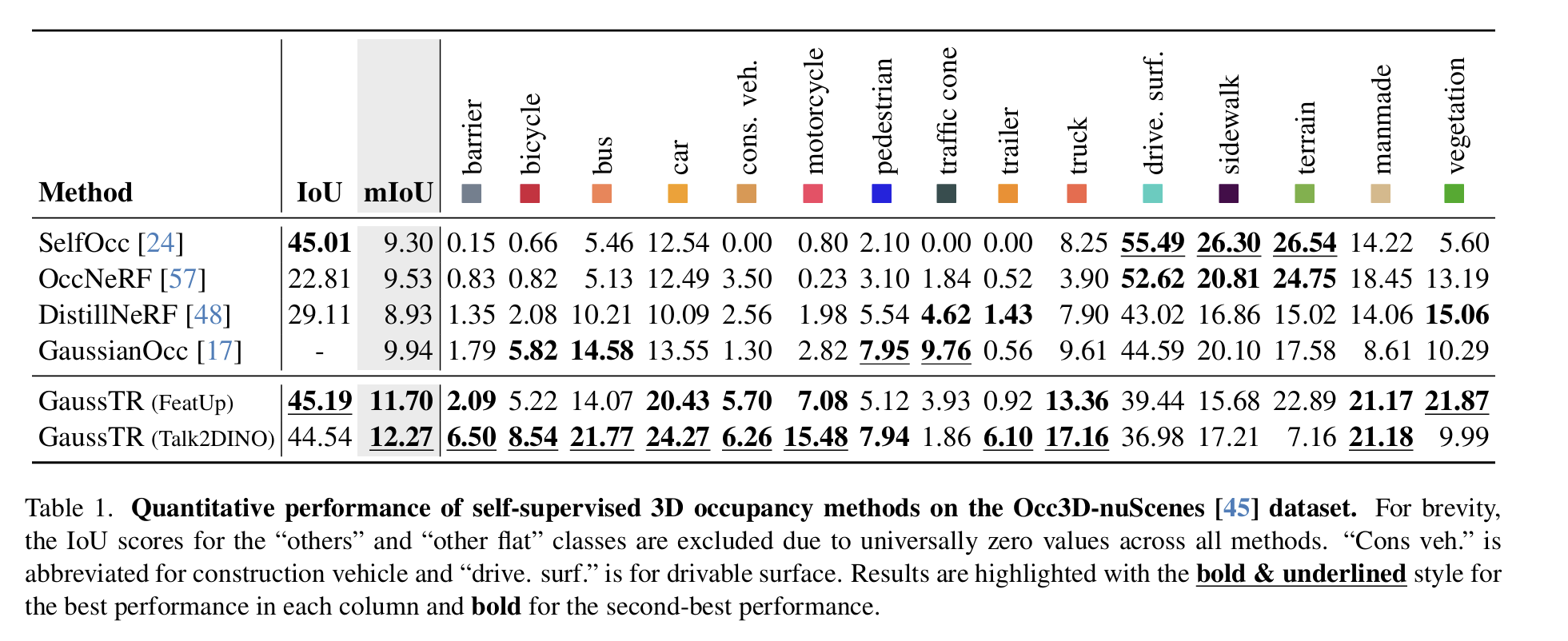
- 顶尖的零样本性能:在 Occ3D-nuScenes 数据集上实现了 12.27 mIoU 的零样本预测性能,比先前的方法高出 23%,同时将训练时间减少了 40%。
本文提出的 GaussTR 中的 Transformer 使用方式非常特别,它并不是传统 ViT 结构那种对图像进行 token 化处理,而是服务于 3D 高斯点的生成与更新。下面我来详细分步骤解释:
📌 GaussTR 中 Transformer 的作用:用于从 2D 多视角特征中生成并优化 3D 高斯表示
🔧 使用 Transformer 的三大阶段
🔹 阶段一:初始高斯查询生成(Gaussian Queries Initialization)
- 起点是摄像头位姿 + 深度图(或假设深度)生成的 初始稀疏点云,用于估算高斯的 初始中心位置(3D 坐标)。
-
每个点会被初始化为一个高斯查询 token,包含以下 learnable 内容:
qi=[position, orientation, scale, density, semantic feature]\textbf{q}_i = \text{[position, orientation, scale, density, semantic feature]}
- 这些 tokens 将被送入后续 Transformer 中进一步学习其结构和语义。
🔹 阶段二:Deformable Cross-Attention:多视图特征对齐
-
用来从多个 2D 视角中提取与每个高斯 token 对应的语义特征。
做法:
对每个高斯中心 $\mathbf{p}_i$:
- 投影到多个 2D 图像;
- 在每张图上从 VFM(如 DINO、FeatUp)提取局部 patch;
- Deformable Attention 聚合这些 patch 特征形成一个跨视角的语义描述。
✅ 类似 DETR 里的 deformable attention,但这里是3D 高斯位置 ←→ 2D 多图像 patch的跨模态映射。
🔹 阶段三:Self-Attention:高斯之间的几何/语义建模
- 所有高斯 token 做一轮标准的 Transformer Self-Attention:
- 捕捉高斯之间的相对空间关系(比如相邻点可能属于同一个物体);
- 聚合跨点的语义特征,有助于整个 3D 表示的结构一致性与上下文理解。
✅ 类似 NLP 中的句子理解,但这里是“3D 高斯点的上下文建模”。
🧠 Transformer 输出什么?
每个 token 经过 Transformer 解码后,会输出:
| 输出分支 | 作用 |
|---|---|
| 位置 $\mu_i$ | 高斯中心坐标 |
| 尺度 $\Sigma_i$ | 高斯空间范围(椭球) |
| 方向 $\theta_i$ | 控制椭球方向(旋转) |
| 密度 $\alpha_i$ | 控制渲染深度/权重 |
| 语义特征 $\mathbf{f}_i$ | 用于后续与文本类别(CLIP Embedding)匹配 |
这些组成了最终的高斯渲染单位。
🔁 整体流程图(来自论文 Fig. 3 概念图解读)
初始估计的高斯位置 (投影/稀疏点云) ↓ [Transformer Encoder-Decoder] ↙ ↘ Deformable-Cross Self-Attention (2D → 3D) (3D context) ↓ 输出 N 个高斯点的结构 + 特征 📊 相比传统 Transformer 的不同点
| 项目 | 常规 ViT / DETR | GaussTR 中的 Transformer |
|---|---|---|
| Token 类型 | 图像 patch / 位置 query | 高斯点(位置 + learnable 特征) |
| 输入维度 | 2D 图像 / 文本序列 | 初始化稀疏 3D 点云 |
| Attention 模式 | 全局或 Deformable in 2D | Deformable 从多视图图像中 sample 特征,Self-Attn 建模 3D 上下文 |
| 输出 | 分类结果 / bbox / mask | 高斯参数(中心、形状、语义向量) |
✅ 总结一句话:
GaussTR 把 Transformer 用作一个 稀疏 3D 表示的生成器:先通过 deformable cross-attention 从多视图图像提取每个高斯的特征,再通过 self-attention 在 3D 中建模上下文,最终一步到位生成一组可用于渲染的高斯点(包含几何 + 语义),实现 稀疏、可微、开放词表的 3D 表示建模。
GaussTR 的自监督方法是这篇文章的核心之一——它完全不使用任何语义标签或实例分割伪标签,却能训练出几何精确、语义清晰的 3D 占据预测模型。这是通过多模态对齐 + 可微渲染 supervision联合完成的。
🔧 自监督训练目标结构图(概念)
多视角图像 文本类别词表 ↓ ↓ [VFM (如 DINO/FeatUp)] [CLIP Text Encoder] 提取图像特征 提取文本嵌入 ↓ ↓ ------------------------------- ↓ | Transformer Decoder + Splatting | | 输出稀疏高斯(位置+形状+语义特征) | ------------------------------- ↓ ↓ 可微渲染回图像平面后进行对齐损失 ✳️ 三个核心的自监督损失项
1️⃣ 几何对齐损失:深度一致性 (Depth Supervision)
- 高斯点被投影回 2D 多视角图像后,生成深度图(由可微渲染模块产生);
- 将其与真实深度图(来自相机 / LiDAR)计算误差。
损失函数:
论文使用SILog损失(Scale-Invariant Log),对尺度不敏感,适合稀疏点云。
$\mathcal{L}{\text{depth}} = \text{SILog}(\hat{D}, D{\text{GT}})$
✅ 目的:强约束每个高斯的位置与尺度,使其在图像中重投影与实际场景结构一致。
2️⃣ 语义对齐损失:视觉基础模型特征对齐 (Feature Matching)
- 渲染回的高斯特征图 $\hat{F}{\text{2D}}$与原始图像通过 VFM 提取的特征 $F{\text{VFM}}$ 进行余弦相似度对齐。
损失函数:
$\mathcal{L}{\text{VFM}} = \sum{x,y} \left( 1 - \cos\left( \hat{F}{\text{2D}}(x,y),\ F{\text{VFM}}(x,y) \right) \right)$
✅ 目的:让高斯语义特征能够表达图像中语义上下文;训练后可与 CLIP 文本向量进行匹配(开放词表预测的基础)。
3️⃣ 辅助监督项:可选的边界 mask 监督(如 Grounded-SAM)
- 对一些实验,作者引入 Grounded-SAM 的分割边界,作为一个软约束:
- 在边界区域内施加更强的深度/特征对齐;
- 或者直接作为前景掩码,过滤背景噪声。
损失不是主干,但在某些 VFM 上能微调性能(见论文消融部分)。
🧠 关键机制:可微高斯渲染(Differentiable Gaussian Splatting)
- 用高斯体素在图像平面上splatting(泼墨)出深度图和特征图;
- 可微方式保证了梯度从 2D 回传到 3D 高斯的各项参数(位置、尺度、密度、特征);
- 这是实现”2D ↔ 3D”桥梁的关键。
✅ 相比 NeRF 的 volumetric rendering,splatting 更快且内存更节省。
🔓 训练时完全不需要这些:
| 不需要的东西 | 替代方案 |
|---|---|
| 语义分割标签 | 用 VFM 特征对齐 |
| 分类伪标签(CLIPSeg 等) | 完全弃用 |
| 三维 bounding box | 不需要 |
| Semantic/Instance GT | 不需要 |
| 标注类别数量 | 推理阶段才接触文本词表 |
✅ 总结一句话:
GaussTR 的自监督本质是:把 3D 高斯可微渲染回 2D,并要求其深度和语义特征与真实图像中的对齐。通过与视觉基础模型 (VFM) 提取的特征对齐,它无需人工标签就能让模型学会几何 + 语义,从而实现”零标签训练、开放词表预测”的全流程 3D 场景理解。