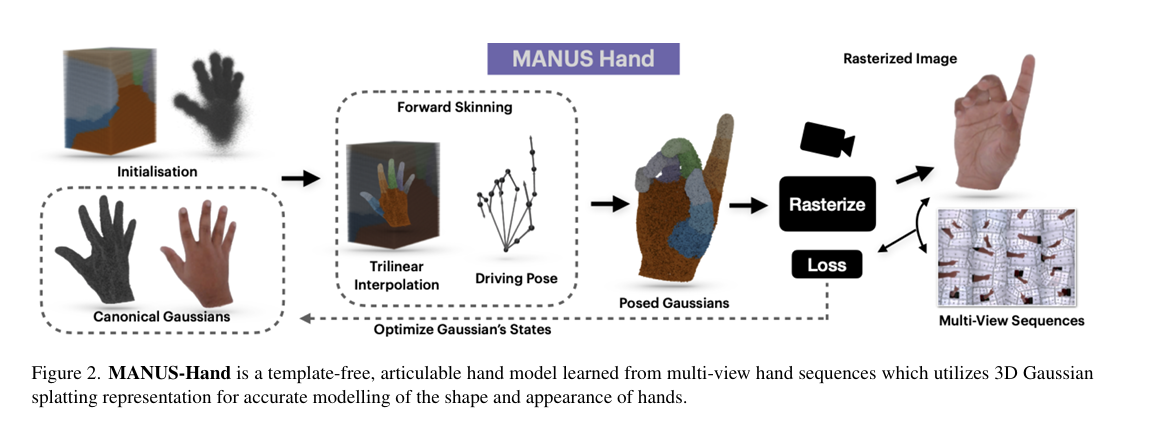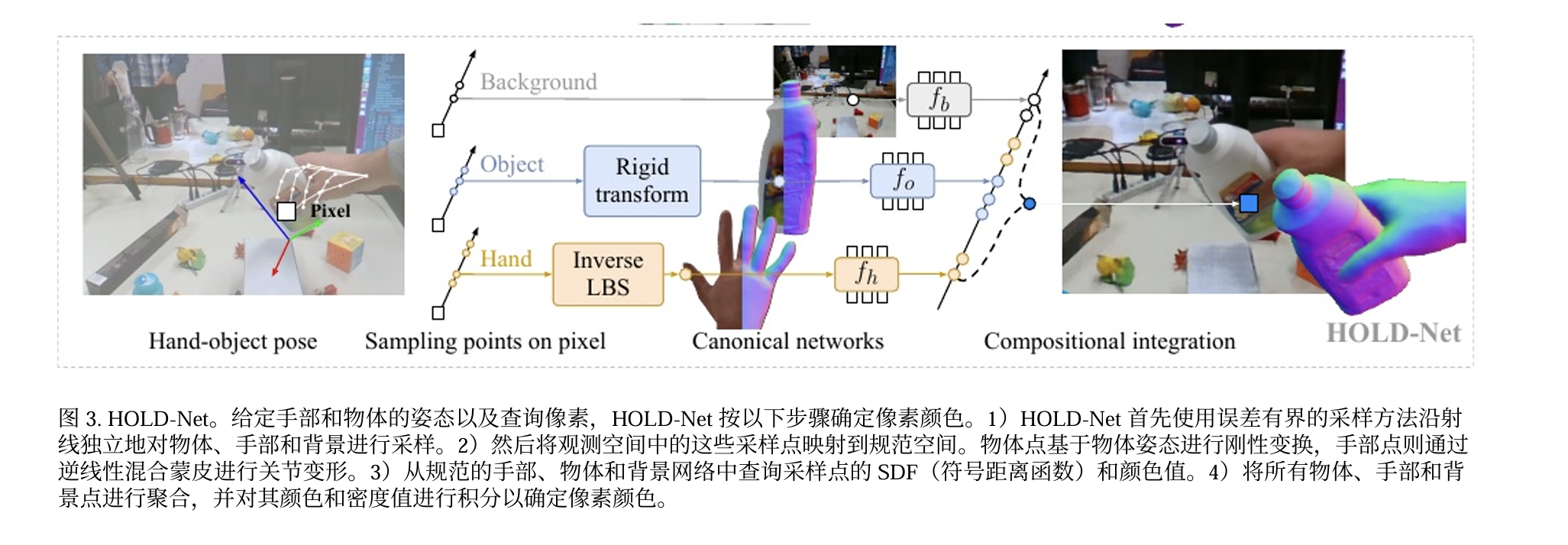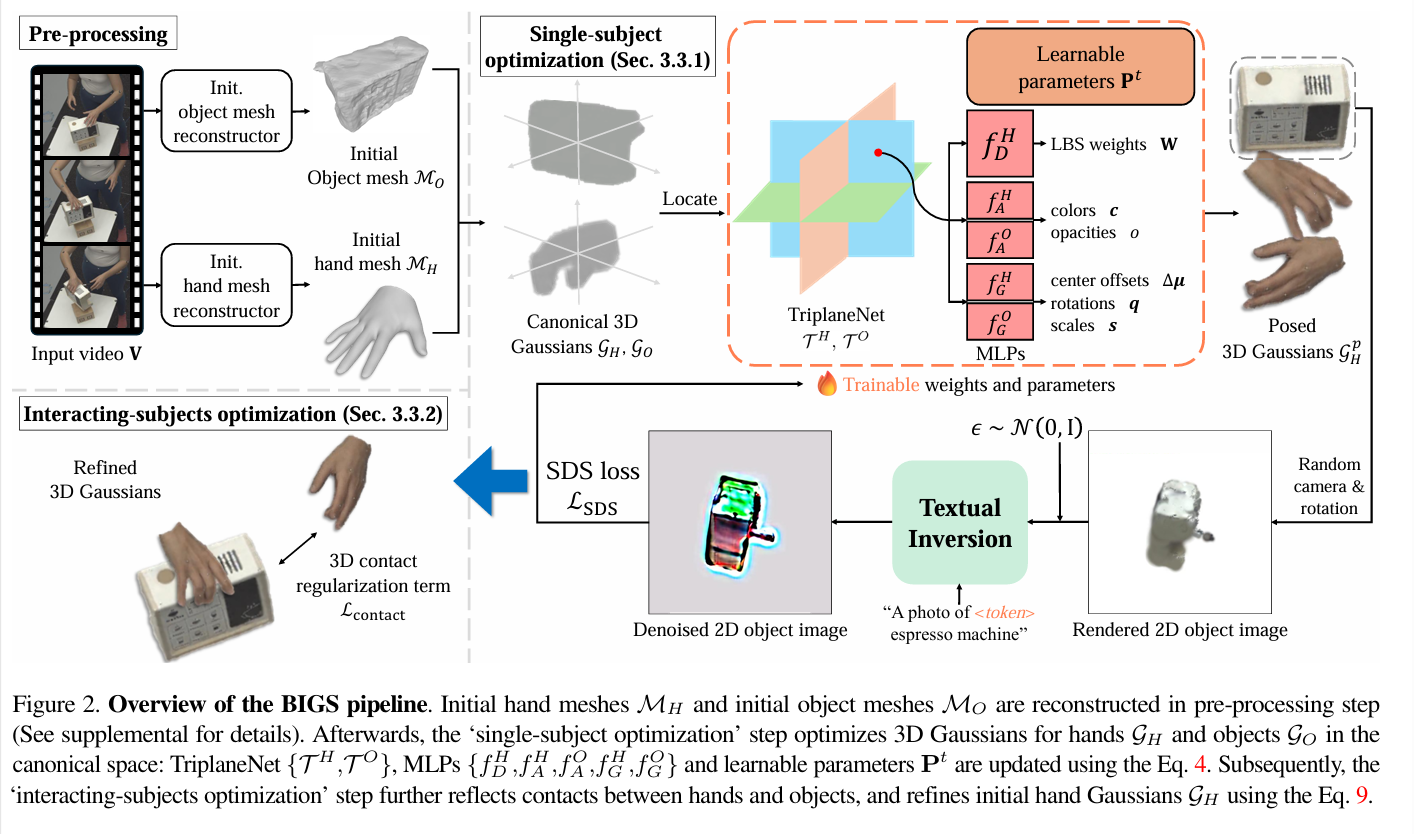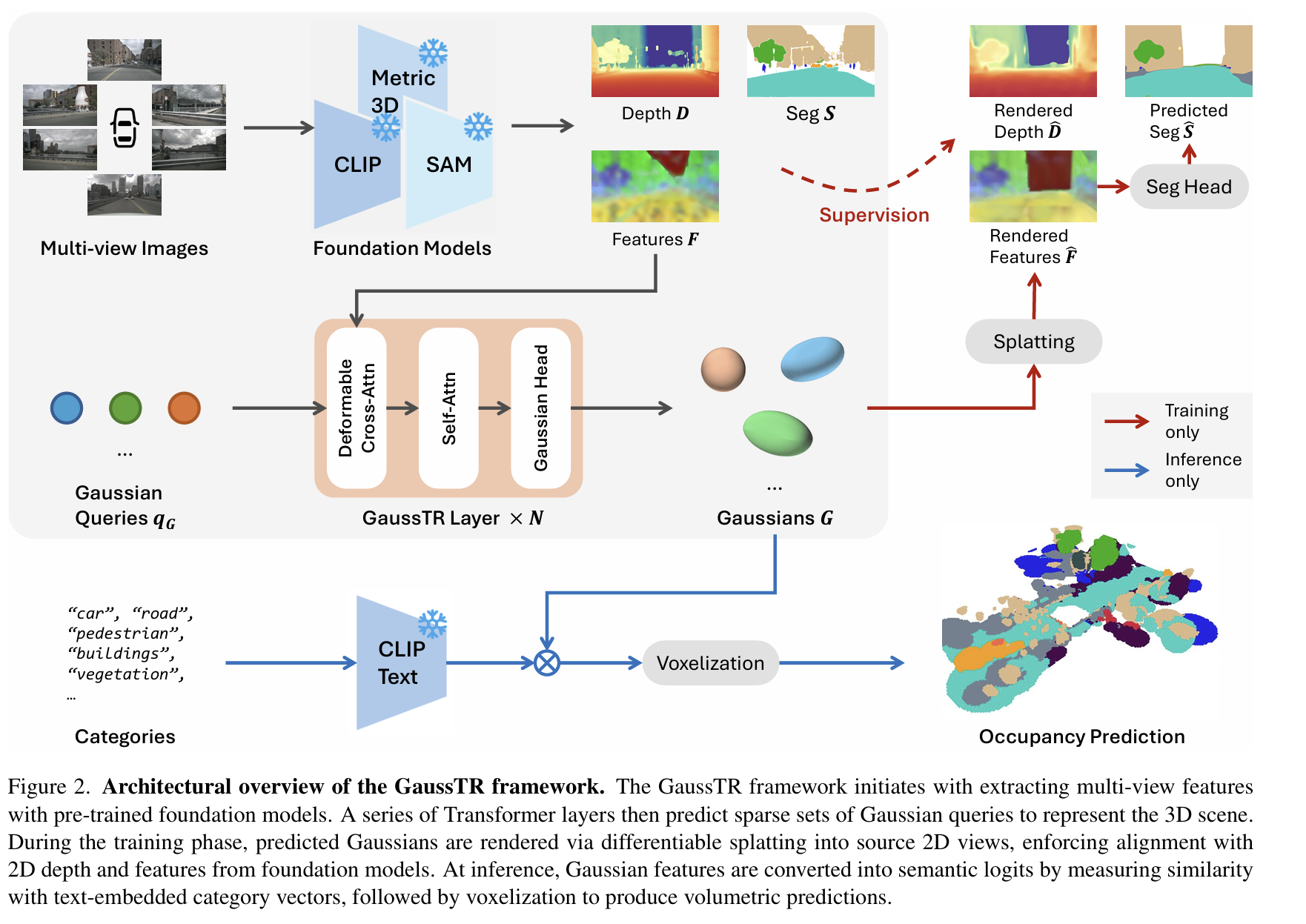
SPLATFORMER: POINT TRANSFORMER FOR ROBUST3D GAUSSIAN SPLATTING
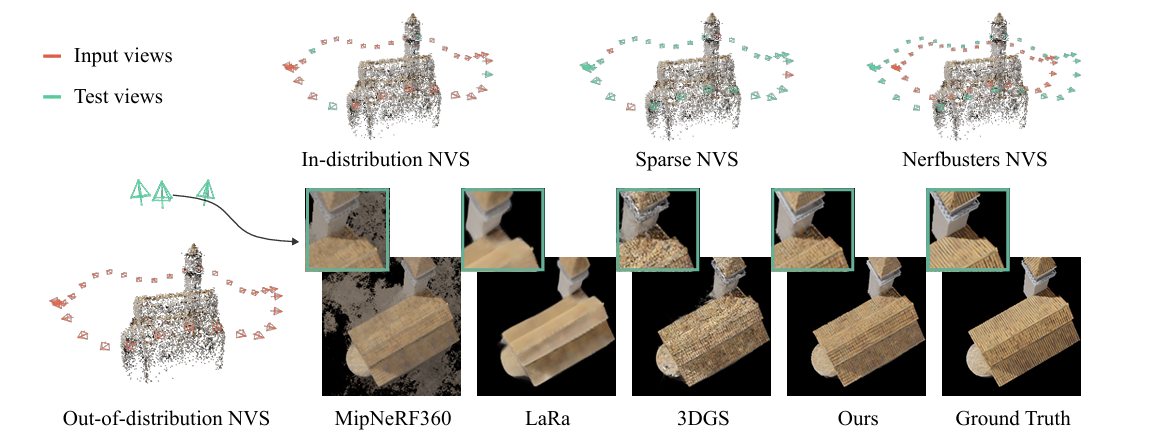
2025 ICLR spotlight(我很喜欢这一篇,Point Transformer我可太熟了) 概括 极端视角下优化gaussian splatting表现 背景: 3DGS的局限性:尽管3DGS技术在生成逼真的三维场景方面表现出色,但它的渲染质量在面对“分布外(Out-of-Distribution, OOD)”的测试视角时会急剧下降。 简单来说,如果你只...